
Table of Contents
Great systems are not just built. They are monitored.
MetricFire runs Graphite and Grafana as a fully managed service for growing engineering teams, taking care of storage, scaling, and version updates so your team doesn't have to. Plans start at $19/month, billed per metric namespace rather than per host, and include engineer-staffed support. Integrations work natively with Heroku, AWS, Azure, and GCP, and data is stored with 3× redundancy in SOC2- and ISO:27001-certified data centres.
Introduction
Monitoring the state of your services and running processes is crucial for ensuring system reliability and early detection of issues, allowing for timely interventions to prevent downtime. It also helps maintain optimal performance by identifying and resolving inefficiencies or errors in the system's operations.
In this article, we'll detail how to use the Telegraf agent to collect systemd service statistics, and forward them to a data source.
Getting Started with the Telegraf Agent
Telegraf is a plugin-driven server agent built on InfluxDB that collects and sends metrics/events from databases, systems, processes, devices, and applications. It is written in Go, compiles into a single binary with no external dependencies, and requires a minimal memory footprint. Telegraf is compatible with many operating systems and has many helpful output plugins and input plugins for collecting and forwarding a wide variety of system performance metrics.
Install Telegraf (Linux/Redhat)
/etc/telegraf/wget https://dl.influxdata.com/telegraf/releases/telegraf_1.30.0-1_amd64.deb
sudo dpkg -i telegraf_1.30.0-1_amd64.deb
RedHat/CentOS
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.30.0-1.x86_64.rpm
sudo yum localinstall telegraf-1.30.0-1.x86_64.rpm
Configure an Output
You can configure Telegraf to output to various sources, such as Kafka, Graphite, InfluxDB, Prometheus, SQL, NoSQL, and more.
In this example, we will configure telegraf with a Graphite output. If you're not currently hosting your data source, start a 14-day free trial with Hosted Graphite by MetricFire to follow these next steps.
A Hosted Graphite account will provide the data source, offer an alerting feature, and include Hosted Grafana as a visualization tool.
To configure the Graphite output, locate the downloaded telegraf configuration file at /etc/telegraf/telegraf.conf and open it in your preferred text editor. Then, you will need to make the following changes to the file:
First, uncomment the line:
[[outputs.graphite]]
Next, uncomment and edit the server line to:
servers = ["carbon.hostedgraphite.com:2003"]
Finally, uncomment and edit the prefix line to:
prefix = "<YOUR_API_KEY>.telegraf"
Locate Active Services to Monitor
This article assumes that you already have active services running in your Linux server(s), so you will to determine which service units you wish to monitor. For this example, a simple bash script will show you how to list all active services (excluding inactive services), and also exclude services that contain invalid characters (like @).
- create a file named list_units.sh:
#!/bin/bash
# List all active systemd service units and exclude those with '@' in their names
systemctl list-units --type=service --state=active --no-legend --no-pager | awk '!/@/ {print $1}' | tr '\n' ' '
- make the script executable: sudo chmod +x list_units.sh
- run the script: ./list_units.sh
Configure the Telegraf Plugin
Telegraf has many input plugins that can collect a wide range of data from many popular technologies and 3rd party sources. In this example, we'll demonstrate how to collect and forward metrics from your systemd active services.
You will need to search for the inputs.systemd_units section in your telegraf.conf file, uncomment that line:
[[inputs.systemd_units]]
Now uncomment the 'pattern' line and define which service units to monitor from the output of your list_units.sh script:
pattern = "<service1>.service <service2>.service <service3>.service"
Then you can run the telegraf daemon using the following command, which will help you see if there are any configuration errors in the output:
telegraf --config telegraf.conf
Telegraf will now forward systemd_units metrics to your configured datasource. This is what the metrics from a single service unit will look like in the Graphite format:
telegraf.<host>.active.loaded.<service>.running.systemd_units.active_code
telegraf.<host>.active.loaded.<service>.running.systemd_units.load_code
telegraf.<host>.active.loaded.<service>.running.systemd_units.sub_code
If you are collecting statistics from ALL services (including inactive), you will get additional datas set for services that are inactive and failed to load. See the official GitHub repository for additional details and configuration options for the systemd_units plugin.
Use Hosted Graphite by MetricFire to Create Custom Dashboards and Alerts
MetricFire is a monitoring platform that enables you to gather, visualize and analyze metrics and data from servers, databases, networks, processes, devices, and applications. Using MetricFire, you can effortlessly identify problems and optimize resources within your infrastructure. Hosted Graphite by MetricFire removes the burden of self-hosting your monitoring solution, allowing you more time and freedom to work on your most important tasks.
Once you have signed up for a Hosted Graphite account and used the above steps to configure your server(s) with the Telegraf Agent, metrics will be forwarded, timestamped, and aggregated into the Hosted Graphite backend.
-
Metrics will be sent and stored in the Graphite format of: metric.name.path <numeric-value> <unix-timestamp>
-
The dot notation format provides a tree-like data structure, making it efficient to query
-
Metrics are stored in your Hosted Graphite account for two years, and you can use them to create custom Alerts and Grafana dashboards.
Build Dashboards in Hosted Graphite's Hosted Grafana
In the Hosted Graphite UI, navigate to Dashboards => Primary Dashboards and select the + button to create a new panel:
Then you can use the query UI in Edit mode to select a graphite metric path (the default data source will be the HostedGraphite backend if you are accessing Grafana via your HG account):
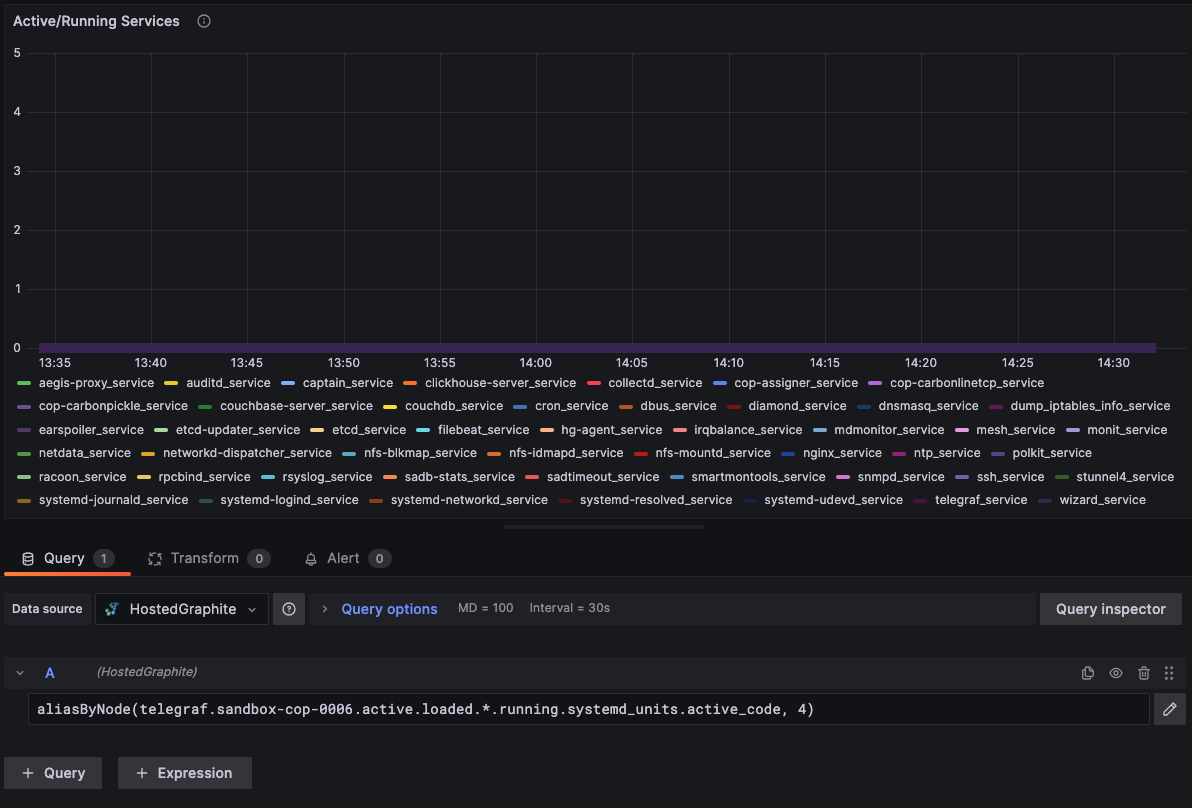
NOTE: The Hosted Graphite datasource also supports wildcard (*) searching to grab all metrics that match a specified path. The Graphite function aliasByNode() was also applied, to reformat the name.
For this example, the State Timeline visualization (Grafana > v8) is useful because you can see if an active service begins reporting null data (indicating that a service has stopped or failed to load - notice the diamond_service as it was stopped, and then restarted):

Additionally, Grafana has many additional options to apply different visualizations, modify the display, set units of measurement, and some more advanced features like configuring dashboard variables and event annotations.
See the Hosted Graphite dashboard docs for more details.
Creating Graphite Alerts
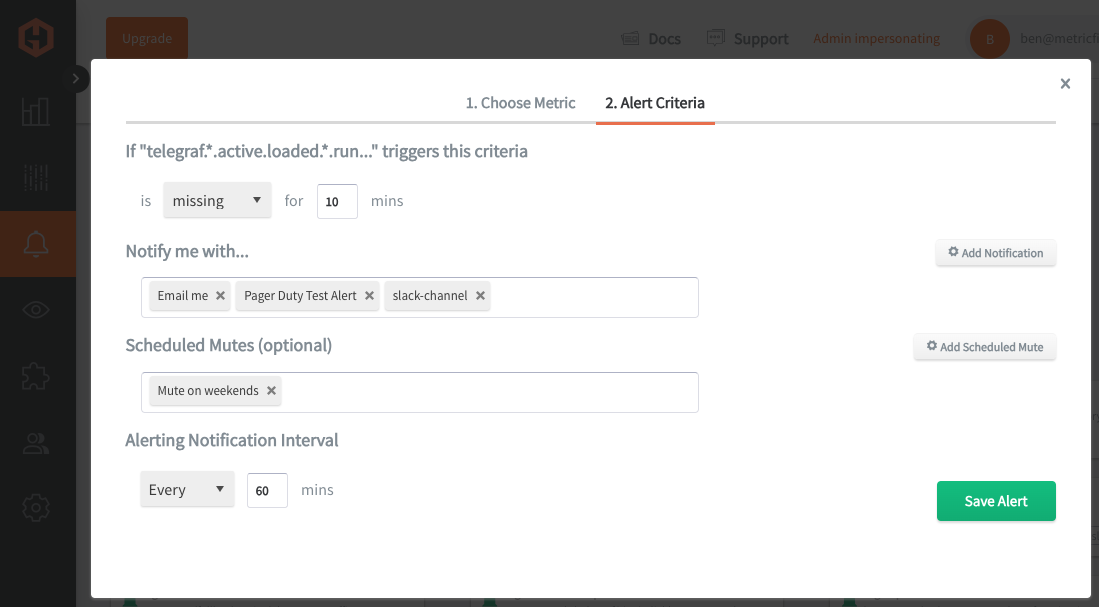
In the Hosted Graphite UI, navigate to Alerts => Graphite Alerts to create a new alert. Name the alert, add a query to the alerting metric field, and add a description of what this alert is:

Then, select the Alert Criteria tab to set a threshold and select a notification channel. The default notification channel will be the email you used to sign up for the Hosted Graphite account. Still, you can easily configure channels for Slack, PagerDuty, Microsoft Teams, OpsGenie, custom webhooks and more. See the Hosted Graphite docs for more details on notification channels:
Conclusion
Monitoring the state of your server's active services is crucial for your business as it ensures continuous availability and performance, minimizing potential disruptions that could impact customer experience and revenue. It also enables proactive management by identifying issues early, allowing for quick resolution before they escalate into more significant problems.
Tools like dashboards and alerts will complement your data by providing real-time visualization, proactive identification of issues, historical trend analysis, and facilitating informed decision-making, all essential for maintaining a robust and efficient infrastructure.
Sign up for the free trial and begin monitoring your infrastructure today. You can also book a demo and talk to the MetricFire team directly about your monitoring needs.

