
Table of Contents
Introduction
Prometheus is an increasingly popular tool in the world of SREs and operational monitoring. Based on ideas from Google’s internal monitoring service (Borgmon), and with native support from services like Docker and Kubernetes, Prometheus is designed for a cloud-based, containerized world. As a result, it’s quite different from existing services like Graphite.
Starting out, it can be tricky to know where to begin with the official Prometheus docs and the wave of recent Prom content. This article acts as a high-level overview of how Prometheus works, its positives and challenges for monitoring, and where MetricFire can help as a Prometheus alternative. You can also try a 14-day free trial of MetricFire.
Key Takeaways
- Prometheus is a popular tool for SREs (Site Reliability Engineers) and operational monitoring, designed for a cloud-based, containerized world.
- Prometheus collects metrics by configuring "scrape jobs," which specify endpoints to scrape or use service discovery to obtain endpoints automatically.
- Metrics are provided to Prometheus by applications through client libraries or exporters that gather metrics from specific applications.
- Prometheus supports two kinds of rules: recording rules and alerting rules, enabling users to create new metrics and set up alerts based on specified criteria.
What is Prometheus and how does it work?
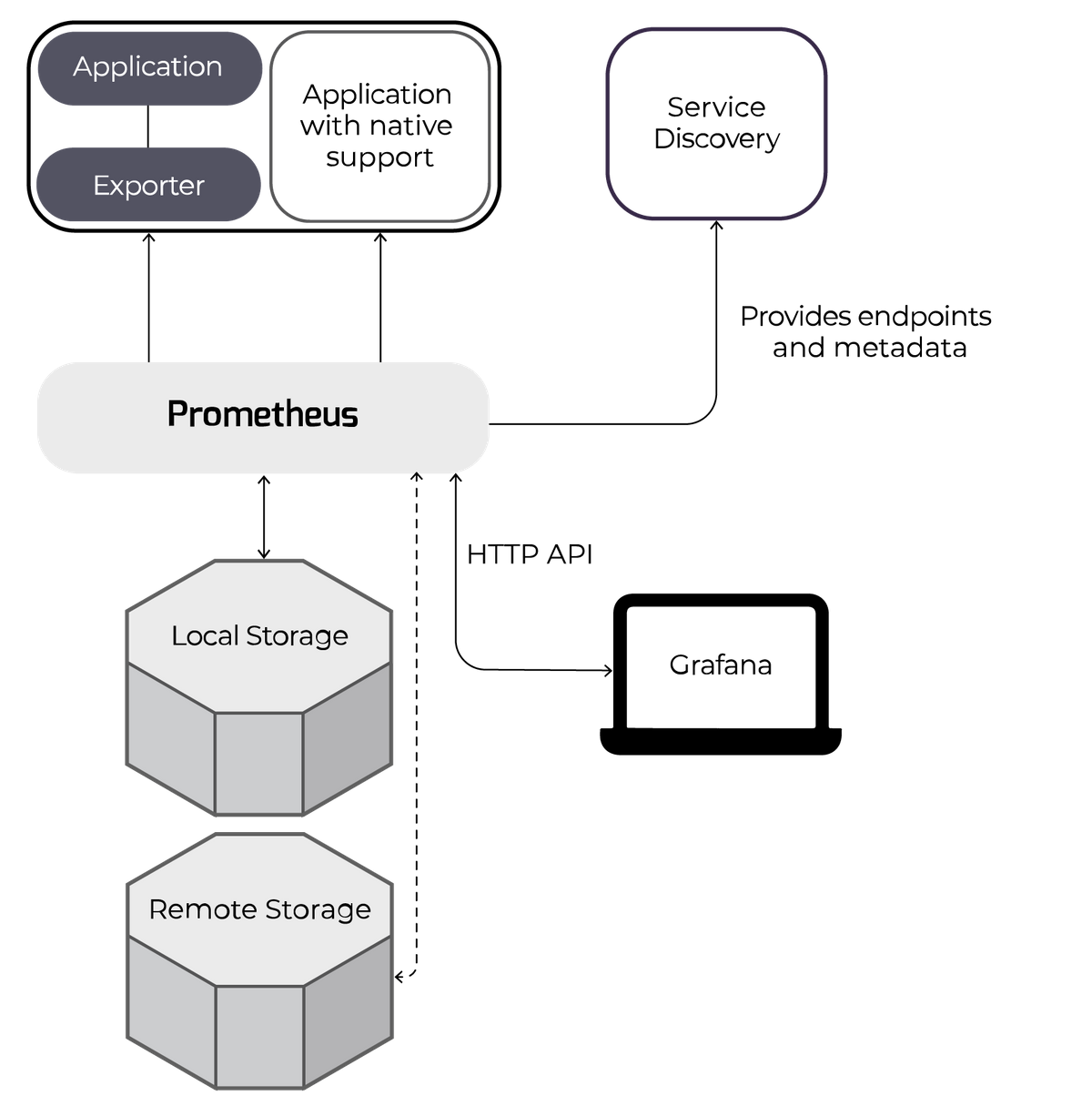
Prometheus is an application (written in Go) that can be run directly on a server, in a docker container, or as part of e.g. a Kubernetes cluster. You tell it where to find metrics by configuring a list of “scrape jobs”. Each job specifies endpoints to scrape or configures service discovery to obtain endpoints automatically. For example, a job to scrape Kubernetes would contain the Kubernetes API server endpoint. The Kubernetes API then returns the endpoints to scrape for current nodes or pods.
Applications can provide these metrics endpoints to Prometheus using client libraries available for various languages. You can also use separate exporters which gather metrics from specific applications and make them available to Prometheus. Each application or exporter endpoint serves up metrics plus tags and appropriate metadata whenever Prometheus requests them.
Official and unofficial exporters exist for dozens of services. A popular one is node_exporter, which collects system metrics for Linux and other Unix servers.
Metrics are stored locally on disk, and by default they’re only retained for 15 days, providing a sliding window of data instead of a long-term storage solution. Prometheus doesn’t have the capability to store the metrics in more than one location. However, since the metrics aren’t consumed when requested, it’s possible to run more than one Prometheus for the same services in order to have redundancy. Federation also allows one Prometheus server to scrape another for data, consolidating related or aggregated data into one location.
Remote storage is another option: Prometheus can be configured with remote_write and remote_read endpoints. Prometheus will regularly forward its data to the remote_write endpoint. When queried, it will request data via the remote_read endpoint and add it to the local data. This can produce graphs that display a much longer timeframe of metrics.
Prometheus also serves as a frontend UI to let you search the stored metrics, apply functions, and preview graphs. Alongside this, an HTTP API can be used by e.g. Grafana as a data source.
Benefits for users
- Service discovery – This is a big plus for Prometheus. Large-scale deployments can change all the time, and service discovery allows Prometheus to keep track of all the current endpoints effortlessly. Service discovery can be achieved via support from various resource management services, such as Kubernetes, Openstack, AWS EC2, and others. There are also generic options for DNS and file-based service discovery.
- Outage detection – since Prometheus knows what it should be monitoring, outages are very quickly detected when the request fails.
- PromQL is an incredibly flexible, Turing-complete, query language. It can apply functions and operators to your metric queries, filter, and group by labels, and use regular expressions for improved matching and filtering.
- Low load on the services being monitored – metrics are stored in memory as they are generated, and only converted into a readable format when requested. This uses up fewer resources than converting every metric into a string to send as soon as it’s created (as you would for a service like Graphite). Also, metrics are batched and sent all at once via HTTP, so the per-metric load is lower than sending the equivalent, even by UDP.
- Control of traffic volumes – push metric services can be overwhelmed by large volumes of data points, but Prometheus only receives metrics when it asks for them – even if the service itself is very busy. Any user of Jenkins has probably seen their metric volumes spike when a batch is processed, however with a Prometheus exporter in place, metrics would still be queried every 15s regardless of how many events are being generated. That keeps your monitoring service safe.
- Metrics in the browser – You can look at the metrics endpoint directly to see what’s being generated at any given time, e.g. Prometheus’ own metrics can be viewed on http://localhost:9090/metrics
- Easy reconfiguration – since Prometheus has the responsibility for obtaining metrics, if there’s a change to the configuration required it only needs to be done in Prometheus instead of changing the configuration for all the monitored services.
Challenges to using Prometheus
- Storage – the standard storage method uses space and resources on your server. This might not be dedicated to Prometheus and could be expensive depending on what platform you’re using (AWS high-IO EBS volumes seem affordable but the costs do mount up!). The actual amount of space taken up by storage is reasonably simple to calculate, and the more services you monitor the more data you store.
- Redundancy – Prometheus saves to one location only, unlike Graphite for example which can save data to storage clusters. Running multiple Prometheus instances for the same metrics is the given solution, but it’s arguably awkward and a little messy.
- No event-driven metrics – each value is a point-in-time retrieved on request, which doesn’t work for short-lived jobs and batches, since metrics will only be available for a short period of time, or intermittently. Prometheus works around this by providing a Pushgateway.
- Limited network access – access restrictions to the resources being monitored may mean that multiple Prometheus services have to be run, since there may not be external access to those resources. That requires connecting to different instances of Prom to view different metrics or using Federation to scrape metrics from multiple Proms into one central server.
Rules and Alerts
Prometheus supports configuring 2 kinds of rules – recording rules and alerting rules. Recording rules allow you to specify a PromQL-style rule to create new metrics from incoming data by applying transformations and functions to the data. This can be great if, for example, you have a large number of metrics to view at once, and they’re taking a long time to retrieve. Instead, you can create a sum () metric on the fly, and you’ll only need to retrieve one metric in the future.
Alerting rules instruct Prometheus to look at one or more metrics being collected and go into an alerting state if specified criteria are breached. The state of alerts is checked just by going to the alerts page in the Prometheus UI; Prom doesn’t have the capacity to send notifications. AlertManager is a service that adds that ability and monitors alerts separately in case the platform a Prometheus server is running on has errors.
How Metricfire Can Help
At Metricfire we provide a hosted monitoring solution. This includes long-term, scalable, storage, in the form of remote_read and remote_write destinations for your existing installations. That means off-disk storage, with redundancy built-in, and extended retention of up to 2 years.
It comes with a hosted Grafana service, which lets you configure your installations as data sources. Alternatively, you can use the Metricfire data source to view stored data from all your servers together, in one place. Each server may generate metrics with the same names and will often consider its own hostname to be localhost:9090. You can use the ‘external_labels’ option in the global configuration to ensure that similar metrics from different servers can be differentiated.
Get onto our free trial and check out what the product looks like - it only takes a few minutes to start using it. Also, get us on the phone by booking a demo.
Questions, comments, or anything we’ve missed? Get in touch: help@metricfire.com


